




 0
0

Some 18 months after Apple implemented ATT and started the ID phase-out, the in-app advertising ecosystem is settling on a new, privacy-first framework: IAB Tech Lab’s Seller Defined Audiences (SDA). The new framework democratizes cohort development for the open ecosystem by allowing app publishers to communicate first-party audience attributes in an OpenRTB bid request. The result is a new competitive landscape, in which publishers with the strongest first party data strategy have the winning position in the competition for advertising dollars.
Pocketing Google’s endorsement earlier this month, SDA is gaining rapid traction. The sudden need for first party data has caught some publishers with their pants down, because user data has historically been collected by advertisers. Ready or not, SDA’s impact is here: Nike can now bid on an inventory of ‘fitness fanatics who just came home from a run’, and publishers who only qualify their inventories based on high level information or general segmentation are likely to struggle to compete.
Publishers, get your playbooks out: it’s a new game with new winners, and your first party data is your ace in the hole (or your Pokeball, if you prefer). Let’s review the playground.
The SDA Game
The SDA framework consists of 3 steps:
- Publisher segments audience
- Publisher includes segment IDs into the bid request
- DSP reads segment IDs and decides whether to bid
Here’s the exciting (or scary) part: publishers can include segment IDs from any taxonomy they choose. Effectively, that means any combination of 3 possible approaches: develop your own, use IAB’s audience taxonomy, or use taxonomies from IAB approved vendors that specialise in on-device audience intelligence.
Which approach is right for you depends on the ecosystem you opperate in: if you are looking to send the data to many other exchanges and DSPs, the IAB taxonomy may be the right choice. But if you mostly sell directly to brands and agencies, a custom taxonomy is likely to be a better fit because it gives you more flexibility and control, allowing you to define your audience in the most accurate possible way.
Custom taxonomies: mobex
One example of a custom taxonomy for on-device intelligence is NumberEight’s Euclid. The technology enriches publishers’ first party data with mobile context (mobex): live user context and behavioural audiences. Let’s take a look at an example to see how mobex would impact an inventory’s competitiveness.
Imagine Coke Zero bids on inventory for the following campaign:
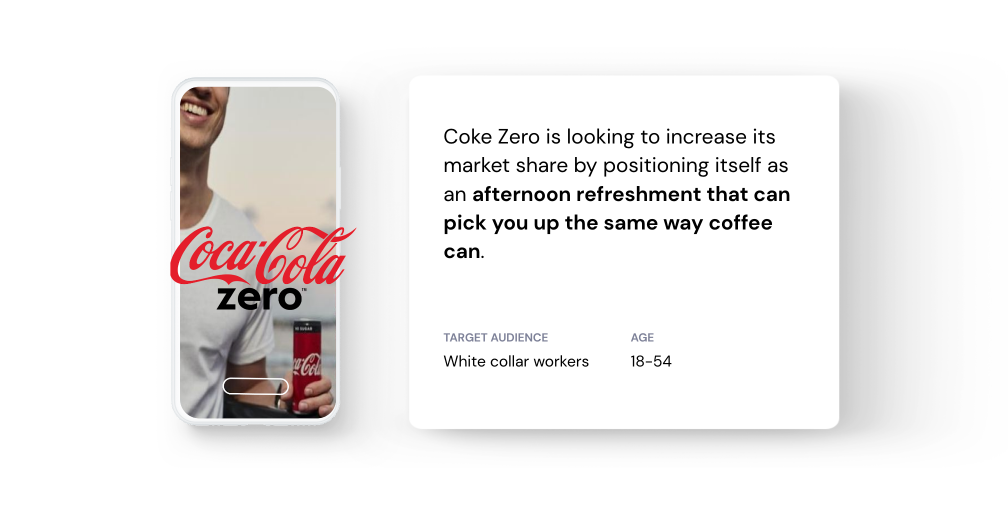
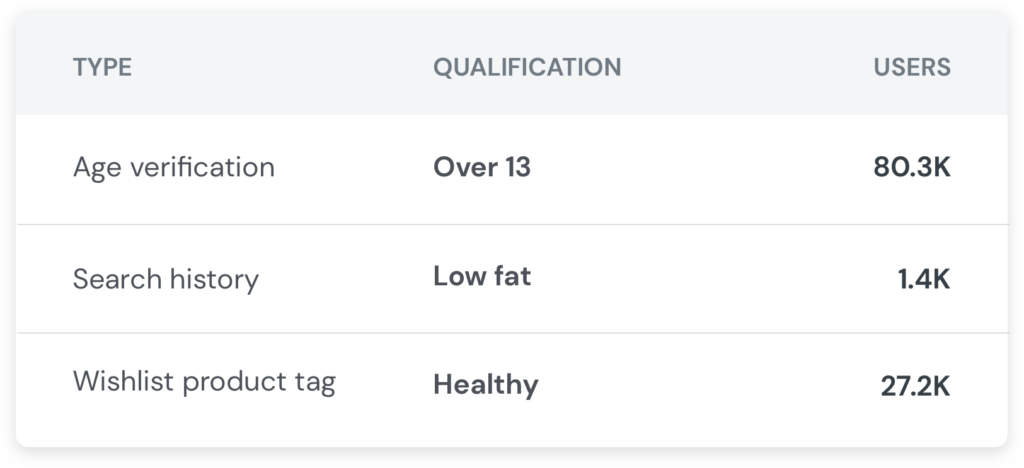
Publisher A currently uses PII from profile settings and an onboarding flow to qualify its audience. They submit the following inventory into the bidrequest:
Publisher B has enriched their first party data with mobex, so their inventory is qualified based on their users’ behavioural patterns and their current context. They submit this inventory into the bidrequest:
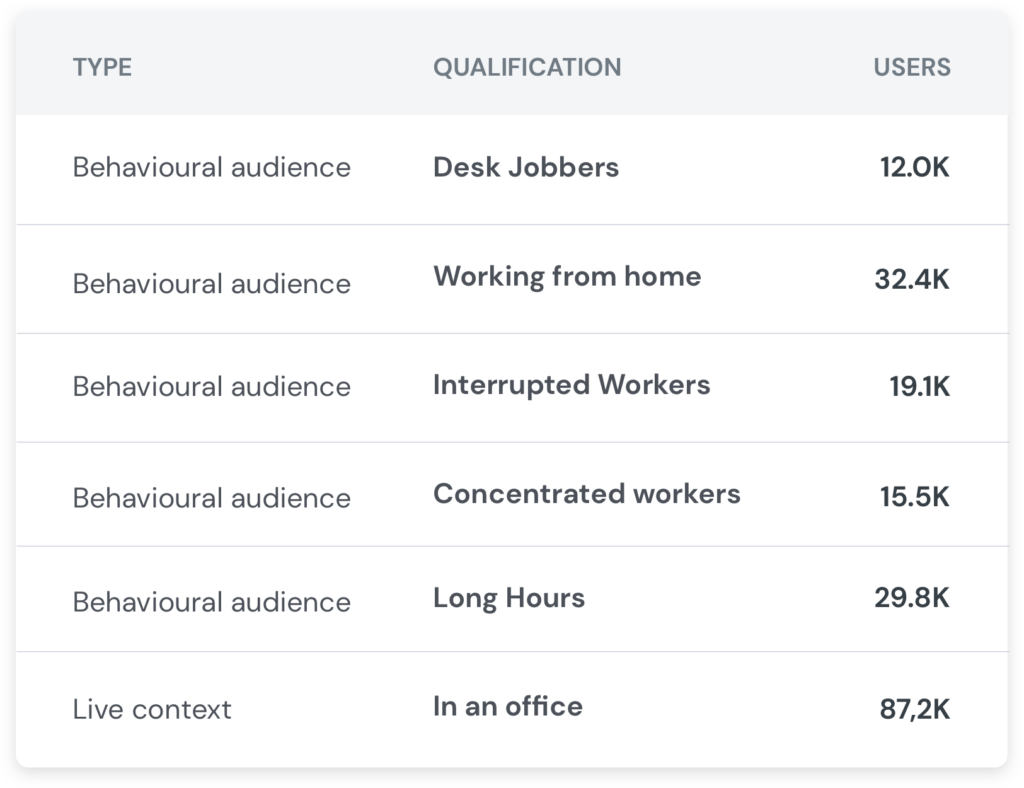
Publisher B will win Nike’s campaign, because each user segment’s behaviour or context directly suggests that they’re a good match for the campaign’s persona.Â
The mobex advantage
Mobex has a two-fold impact on your ad revenue.
Firstly, as we saw in the above example, it allows you to win more bids by putting your inventory on steroids. Advertisers prefer mobex-enriched inventory because it allows them to:
- Target more accurately: the relevancy of the user segments is much higher, because they are based on users’ live behavioural patterns and current context, rather than high level information.
- ​​Customize their messaging: behavior-based audiences allow advertisers to maximize conversions by developing custom messaging that speaks to each audience’s unique purchase intent. While ‘Interrupted Workers’ may respond to a message like “Need a pick me up? Take a break with Coke No Sugar”; for ‘Concentrated Workers’ a message along the lines of “Take a break! After a long day of sitting in front of a computer, you’ve earned a pick me up” may resonate more.
Secondly, because mobex doesn’t use any IDs, it makes your entire audience addressable again – including the 80% of iOS users that went dark after the disappearance of the IDFA. Assuming an average iOS userbase share of 30%, that means you’ll have 35% more addressable inventory to send into the bidstream.
Sounds pretty good, right? And because mobex sits on the users’ device inside your app, it makes you immune to the ongoing clamp-down on user IDs.
Curious which behavioral audiences and live context can be accessed? Download our taxonomy.
How does mobex work?
Unlike regular data in which recency and relevancy are unknown, mobex data is live, allowing users to be any facet of themselves when a bid request is sent. Consider a person who makes long hours at the office, and likes to go to the beach in their downtime. If a bidrequest goes out while they’re at the office, they’ll be classified as a hard worker – but if it goes out during leisure time, they’ll be considered a beach bum.
Essentially, mobex changes as quickly as the people it’s based on. It queryies the device in the moment a bid request is sent, to understand who a user is right now and what is most important to them at this very moment.
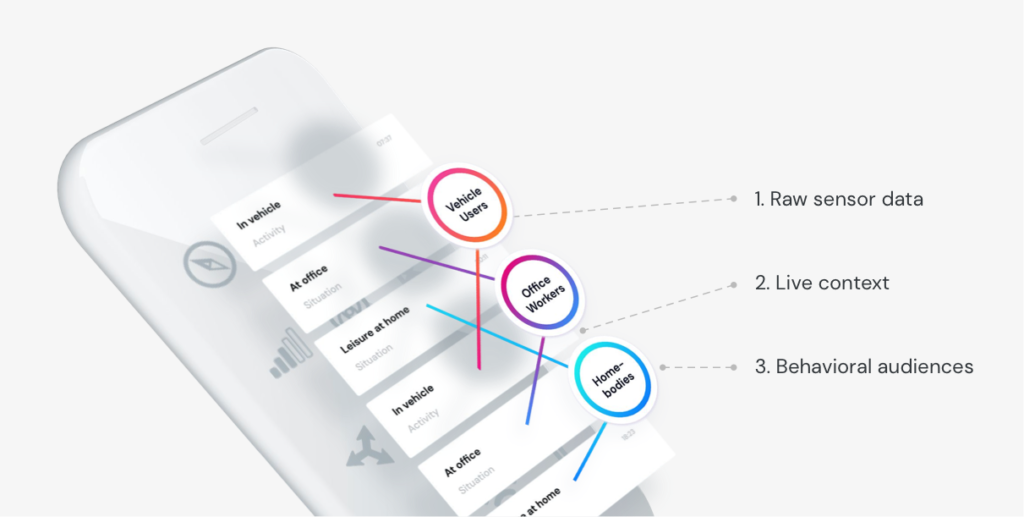
Mobex is built up of three layers:
- Raw sensor data such as gyroscope and magnetometer data is collected by the device
- Live contexts such as running, working, or out with friends are predicted based on the available sensor data
- Behavioural audiences such as luxury supermarket shopper, frequent flyer, or couch potato are calculated from live context over a period of time
The technology sits inside your app and uses available sensor data, so there’s no need to ask your users for additional permissions. Plug & play, baby!
Try before you buy
If you’re curious to see what mobex can do for you, book a demo and ask us about our one-month free trial. If you prefer to test the tech yourself, you can download our demo app and find out which audience categories you fall into.


